


 Всё те же старые песни о главном, а именно про оптимизацию серверов, сверх нагрузки и т.п.. Сегодня вспомним о том, нафига нам robots.txt и как он помогает защитится от DDOS атак роботов.
Всё те же старые песни о главном, а именно про оптимизацию серверов, сверх нагрузки и т.п.. Сегодня вспомним о том, нафига нам robots.txt и как он помогает защитится от DDOS атак роботов.
robots.txt служит для управления поведением порядочных (те которым не пофигу robots.txt) поисковых роботов. Обычно его создают с несколькими директивами да и забивают на это дело, но да неодним-двумя Disallow-ами будут сыты роботы...
Поначалу как-то забивал на сей магический robots.txt файл, ну валяется robots.txt с несколькими директивами да и ладно, но после того как обратил внимание на геометрическую прогрессию роста error_log, а также статистику гугли по индексу сайта в более чем 9.000 тыс. страниц более 8.500 из которых были помечены как "Повторяющееся метаописание" и "Повторяющиеся заголовки (теги title)", то я сразу же во всей красе оценил теоретические и практические преимущества использования robots.txt
Как выяснилось гугля ходит не только по ссылкам, а ходит этот робот ещё и по куче всяких не существующих на сайте адресов куда его никто не приглашал, что в статистике сканирования "Инструменты для веб-мастеров - Состояние - Ошибки сканирования" выливается в более чем 109.468 тыс. ошибок 404:
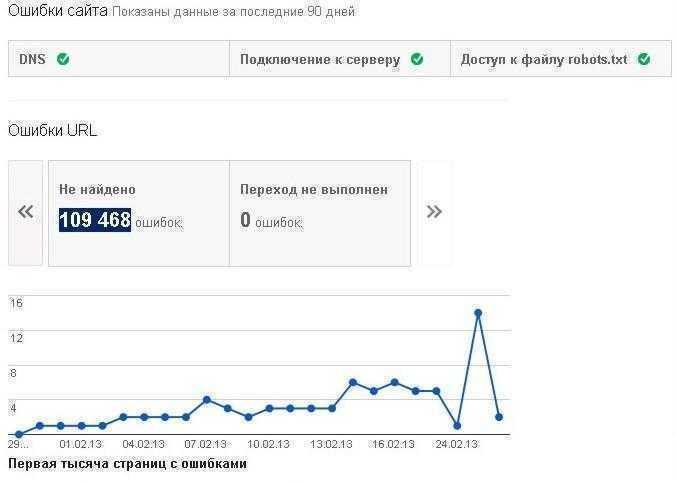
Такая себе самодеятельность раздувающая логи веб сервера:
................................ [Sun Feb 24 09:49:44 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/et [Sun Feb 24 09:51:33 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/ga [Sun Feb 24 09:52:03 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/hr [Sun Feb 24 09:52:06 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/eu [Sun Feb 24 09:58:03 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/hr [Sun Feb 24 09:58:05 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/ht [Sun Feb 24 09:58:37 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/hr [Sun Feb 24 09:59:23 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/hr [Sun Feb 24 09:59:25 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/ga [Sun Feb 24 10:00:12 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/ga [Sun Feb 24 10:00:23 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/lt [Sun Feb 24 10:01:29 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/ga [Sun Feb 24 10:05:19 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/hr [Sun Feb 24 10:05:21 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/ht [Sun Feb 24 10:05:36 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/lt [Sun Feb 24 10:06:30 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/eu [Sun Feb 24 10:06:31 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/yi [Sun Feb 24 10:09:06 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/ht [Sun Feb 24 10:09:08 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/hr [Sun Feb 24 10:09:20 2013] [error] [client 66.249.74.168] File does not exist: / var/www/public_html/lt [Sun Feb 24 10:13:28 2013] [error] [client 66.249.74.158] File does not exist: / var/www/public_html/hr ................................ [Sun Feb 24 10:30:33 2013] [error] [client 66.249.74.158] File does not exist: / var/www/wrs/public_html/hr [Sun Feb 24 10:31:43 2013] [error] [client 66.249.74.158] File does not exist: / var/www/wrs/public_html/ga [Sun Feb 24 10:35:21 2013] [error] [client 66.249.74.158] File does not exist: / var/www/wrs/public_html/hr
Выходит, что гугля автоматом и без приглашения сканирует наличие языковых версий для сайта. Увидев такую картину я сразу же кинулся в robots.txt прописывать Disallow-ы для всех этих урлов
По предварительной информации из access_log гугля и другие боты (например BING от мацдая) гульчитают robots.txt по несколько раз в день или как минимум один раз в сутки (24 часа):
................................ 65.55.24.236 - - [24/Feb/2013:03:53:04 +0200] "GET /robots.txt HTTP/1.0" 200 191 78 ................................ ................................ 66.249.74.158 - - [24/Feb/2013:10:06:19 +0200] "GET /robots.txt HTTP/1.0" 200 19 920
Статистика же в гугле аккаунте "Инструменты для веб-мастеров" по состоянию на "24/Feb/2013:11:30" говорит, что последняя загрузка robots.txt была "22 февр. 2013 г" (всё время по Киеву) - видимо статистика в акаунте явно обновляется не в реальном времени, а один раз в несколько суток.
Так или иначе спустя пол часа после считывания гуглей robots.txt, попытки гугли посетить несуществующие урлы на сайте прекратились. Основные ограничения для ботов получились такие:
User-agent: * Disallow: /?* Disallow: /*.css Disallow: /*.js Disallow: /*.gif Disallow: /*.jpg Disallow: /*.jpeg Disallow: /*.png Disallow: /*.zip Disallow: /*.rar Disallow: /*.pdf Disallow: /*print=1* Disallow: /*task=edit* Disallow: /*format=pdf* Disallow: /*option=com_mailto* Disallow: /*controller=tagging&view=tagging* Disallow: /*option=com_community&view=profile* Disallow: /*option=com_community&view=friends* Disallow: /index2.php Disallow: /administrator Disallow: /cache Disallow: /components Disallow: /images Disallow: /includes Disallow: /installation Disallow: /language Disallow: /libraries Disallow: /media Disallow: /modules Disallow: /plugins Disallow: /templates Disallow: /tmp Disallow: /xmlrpc Disallow: /ar Disallow: /af Disallow: /az Disallow: /fi Disallow: /be Disallow: /bg Disallow: /ca Disallow: /cs Disallow: /cy Disallow: /da Disallow: /de Disallow: /el Disallow: /es Disallow: /en Disallow: /eu Disallow: /et Disallow: /gl Disallow: /ga Disallow: /fr Disallow: /fa Disallow: /is Disallow: /it Disallow: /iw Disallow: /id Disallow: /hi Disallow: /hu Disallow: /hy Disallow: /ht Disallow: /hr Disallow: /ka Disallow: /ko Disallow: /lv Disallow: /lt Disallow: /mt Disallow: /mk Disallow: /ms Disallow: /nl Disallow: /no Disallow: /pl Disallow: /pt Disallow: /ru Disallow: /ro Disallow: /sk Disallow: /sl Disallow: /sv Disallow: /sr Disallow: /sq Disallow: /sw Disallow: /tl Disallow: /tr Disallow: /th Disallow: /ja Disallow: /uk Disallow: /ur Disallow: /vi Disallow: /yi Disallow: /zh-TW Disallow: /zh-CN
В примере выше для этого сайта закрыли доступ ко всем страницам модуля /index.php?option=com_customproperties* (com_customproperties) ибо он выводит список материалов по выбранным тегам и при этом слегка модифицирует ссылки ("id=101:sata" > "id=101%253Asata") на материалы или дописывает в них свои параметры, что приводит к увеличению внутренних ссылок на один и тот же материал, а гугля в свою очередь "Инструменты для веб-мастеров - Оптимизация - Оптимизация HTML" заносит их в "Повторяющееся метаописание" и "Повторяющиеся заголовки (теги title)".
Также лучше ботам запрещать индексацию анонсов (типа секции/категории), календарей и т.д. через мета тэг <meta name="robots" content="noindex, follow" /> - это во-первых снизит нагрузку на сервер, а во-вторых снизит количество отказов, т.е. когда пользователь заходит якобы на искомый материал, а попадает на страницу анонсов в разделе/категории/архиве, которая уже давно неактуальна и не найдя желаемого возвращается к поиску нажимая "Назад" (называется отказ) или просто закрывает страницу, что отрицательно сказывается на репутации сайта как в глазах поисковых систем так и в системах статистики/рейтингах.
Заключение
Полное отсутствие в корне сайта "магического" файла robots.txt или его неправильное составление может стать незаметной причиной перерасхода трафика и физических ресурсов, а также может быть причиной понижения рейтинга в поисковых системах воспринимая дублированный контент как спам.
robots.txt - это важно!
Ссылки по теме
- The Web Robots Pages
- Использование robots.txt - Яндекс.Помощь: Вебмастер
- Робот Googlebot обнаружил слишком много URL-адресов на вашем сайте - Cправка - Инструменты для веб-мастеров
- Блокировка и удаление страниц с помощью файла robots.txt - Cправка - Инструменты для веб-мастеров
- Robots meta tag and X-Robots-Tag HTTP header specifications - Webmasters — Google Developers