


 К перечню компьютерных игр, за последнее время лидерство в которых машины отобрали у человека, можно отнести еще одну - культовую стрелялку Quake 3 Arena. Google DeepMind огласила о искусственном интеллекте, который способен играть в данную игру лучше человека. Ометим, что разговор о режиме, в котором чтобы победить надо завладеть вражеским флагом и переправить его на свою базу - это режим Capture The Flag (CTF) (захват флага).
К перечню компьютерных игр, за последнее время лидерство в которых машины отобрали у человека, можно отнести еще одну - культовую стрелялку Quake 3 Arena. Google DeepMind огласила о искусственном интеллекте, который способен играть в данную игру лучше человека. Ометим, что разговор о режиме, в котором чтобы победить надо завладеть вражеским флагом и переправить его на свою базу - это режим Capture The Flag (CTF) (захват флага).
Как и в случае с иными похожими планами создания искусственного интеллекта для тех либо других 3D-игр, основная трудность тут состоит в том, дабы не имея точных топографических координат научить бота ориентироваться на огромных трехмерных просторах, не имея точных топографических данных - т.е. без карты бродить по местности.
Разработчики DeepMind применили способ так званого "обучения с усилением" (reinforcement learning), который в даной отрасли уже стал стандартом. Подобным способом училась система AlphaGo и остальные механизмы, обыгравшие людей в нескольких компьютерных играх Atari. Главное данного способа от стандартного машинного обучения состоит в том, что искусственный интеллект учится в процессе взаимного действия с окружающим миром не на основе фиксированных/статистических данных, а способом научного тыка путём проб и ошибок.
О самой игре и что в ней надо творить бот в самом начале обучения бот не имеет ни мельчайшего понятия, и во всем радупляться ему нужно самостоятельно. Как правило в противники одному боту ставят иного, и они начинают меж собою холиварить. Однако DeepMind приняла решение пойти иным путем и для достижения более широкого разнообразия стилей игры сформировать групповушку из 30 ботов.
Сколько игр понадобилось сыграть, дабы вырулить на более-менее приличный уровень обученности? примерно 0,5 миллиона каждая длительностью по 5 минут, что отняло 1736 дней на обучение.
Сама идея, лежащая в основе данного способа, казалось бы, проста как двери, однако итоги впечатляют. Боты DeepMind сумели не только вкурить суть и цель игры, однако и собственными силами осилили и проработали различные тактики, которые подразумевают коллективные нападения на базу врага, защиту собственного флага и согласованную командную игру.
Значимый момент в том, что для каждой следующей игры процедурно генерировалась полностью новая карта, что поощряло ботов к наработке подходящих к той либо другой карте различных стратегий.
Боты deepmind, в отличие от ботов OpenAI созданных для игры Dota 2, не имели доступа к числовой БД – потокам чисел, которые отображают такие сведения, как шкала здоровья и дистанция между противниками. Они обучались игре подобно человеку — тобишь наблюдая лишь за дисплеем. Однако это всё совсем не значит, что DeepMind круче ботов OpenAI - Dota 2 куда более сложная игра, нежели кастрированная версия Quake III, которая применялась в обучении ботов DeepMind.
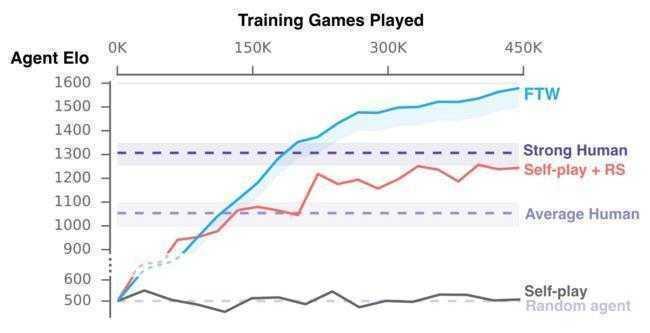
Шкала, которая отражает уровень игры различных игроков - людей. FTW — играющие против друг друга боты DeepMind в группе из 30 игроков.
Чтобы оценить возможности ботов разработчики DeepMind организовали соревнование, в которых компании из нескольких игроков (оба человека, оба бота, бот + человек) боролись друг против друга. В результате лучший итог продемонстрировала команда из обеих игроков ботов. Оценка вероятности её выигрыша составляла 74% против 52% у профессиональных игроков и 43% у средних игроков. Короче говоря, можно констатировать, что электронная вычислительная машина (ЭВМ, компьютер) в игре Quake III, по крайней мере в режиме захвата флага, уже не уступает человеку.
Также отметим, что в командах где игроков было больше боты хуже играли. К примеру, вероятность выигрыша команды из четырех ботов составляла уже 65%. По-этому, боты хоть и получили основные знания о командной работе, но ндля масштабирования на более сложную командную работу их оказалось маловато, а следовательно есть еще над чем поработать. Так или иначе, целью данного проекта, как и любого иного в данной отрасли, заключается совсем не в том, дабы одержать победу над человечеством в компьютерных играх, а в поиске нового метода обучения искусственного интеллекта разбираться в непростой обстановке и достигать поставленные цели. Иначе говоря, разговор идет про обучение с применением интеллекта коллективного, который (невзирая на обилие улик свидетельствующих об обратном) постоянно считался неотделимой составной триумфа человеческого вида.
Приобретённая Google в 2014 году за $400 миллионов компания DeepMind, осуществляет разработки в сфере ИИ. Прежде DeepMind изобрела механизм AlphaGo, который смог одержать победу над человеком в игре го. Предполагалось, что создание искусственного интеллекта для данной игры является одной из особенно трудных задач в данной сфере.